没关系,由乃会保护小雪的对吧,小雪~
人总有一天都会死的,但正因为生命是有限的,才能够欢喜和悲伤。
十九岁以前把这辈子没机会看的书看了,十九岁以后把以前没机会看的电视补上
悲剧将人生的有价值的东西毁灭给人看,喜剧将那无价值的撕破给人看。
树敌真的很容易,有时候简单到令人痛心1111
当经历了背叛亲离,生死一线,失而复得,才明白不再逃避.
http://www.haotui.co
教育不111是灌输,而是点燃火焰
有时我沉默,不是不快乐,只是想把心净空有时候jdjd你需要退开一点,清醒一下,然后提醒自己,我是谁,要去哪里
走你正在走的路,不要怕没人与你分享
如何部署
111222333
开玩笑的啦。时间还不够
后台密码是什么啊
时间再拉长一点,让我有时间收拾一下心情
首页
工具箱
统计
魁拔专区
更多
关于
友链
每日新闻
视频
高清壁纸
Search
1
基于国外服务器搭建自己的VPN详细教程
6,786 阅读
2
最新tvbox绿豆盒子UI8影视APP源码新增后台添加直播及加密功能
3,362 阅读
3
2023彩虹易支付最新原版开源网站源码,完整的易支付源码,无后门
3,170 阅读
4
全新版本码支付个人免签支付系统源码 ThinkPHP框架开发 全开源(亲测)
3,018 阅读
5
多功能强大发卡平台,仿淘宝商城,资源站,一体化平台源码(亲测)
2,971 阅读
🥃技术分享
📠源码分享
📚课程分享
🗃号卡套餐
💾软件仓库
🔥活动线报
✨值得一看
Search
标签搜索
源码分享
技术分享
源码
css
安卓软件
小程序
课程分享
活动线报
软件
电脑软件
号卡
PHP
值得一看
HTML
js
AI
主题
开源
github
教程
老K博客
累计撰写
639
篇文章
累计收到
485
条评论
今日撰写
0
篇文章
首页
栏目
🥃技术分享
📠源码分享
📚课程分享
🗃号卡套餐
💾软件仓库
🔥活动线报
✨值得一看
页面
工具箱
统计
魁拔专区
关于
友链
每日新闻
视频
高清壁纸
用户登录
登录
搜索到
130
篇与
的结果
2024-12-09
如何保证API接口安全?
一、背景介绍在实际的业务开发过程中,我们常常会碰到需要与第三方互联网公司进行技术对接,例如支付宝支付对接、微信支付对接、高德地图查询对接等等服务,如果你是一个创业型互联网,大部分可能都是对接别的公司api接口。当你的公司体量上来了时候,这个时候可能有一些公司开始找你进行技术...
2024年12月09日
275 阅读
0 评论
0 点赞
2024-12-08
信息搜集:原来黑客都是这样使用搜索引擎
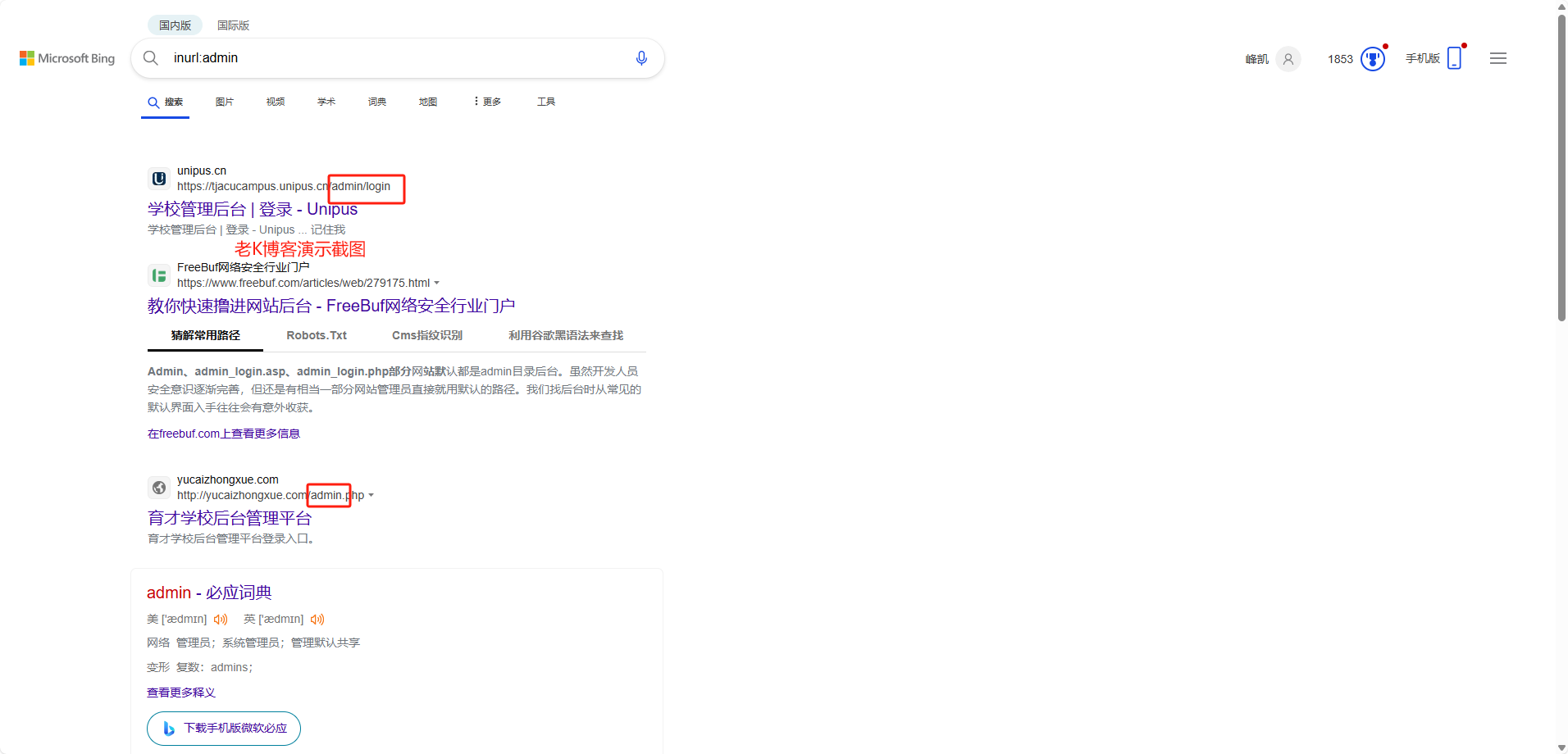
声明:本文仅用于合法范围的学习交流,若使用者将本文用于非法目的或违反相关法律法规的行为,一切责任由使用者自行承担。请遵守相关法律法规,勿做违法行为!{mtitle title="搜索引擎语法"/}请使用Bing或Google搜索引擎进行搜索。1、inurl:关键字 (查找包...
2024年12月08日
2,026 阅读
0 评论
0 点赞
2024-11-27
GZ::CTF一站式解决方案!别再为搭建 CTF 平台发愁了!
随着网络安全竞赛的飞速发展,CTF平台部署/运维领域挑战重重,GZ::CTF作为一款基于 ASP.NET Core 开发的开源 CTF 平台,它不仅满足了 CTF 比赛组织者的核心需求,更通过创新的设计和技术拓展了竞赛的边界。您是否遇到过?比赛系统搭建太繁琐,调试比比赛本身...
2024年11月27日
377 阅读
0 评论
0 点赞
2024-11-06
python批量图片转webp格式
主要流程就是将非webp的图片转换后丢到指定目录,已经是webp的就直接丢过去。有三个参数, input_folder , output_folder , qualityinput_folder你要转换的图片文件夹output_folder转换后输出的路径quality...
2024年11月06日
434 阅读
0 评论
0 点赞
2024-11-04
使用 C# 和 SQL Server 实现数据库的实时数据同步
在现代应用程序中,及时更新不同数据库之间的数据至关重要。本文将介绍如何在 SQL Server 中使用 C# 实现数据的实时同步。我们将使用 SQLDependency 类来监听数据库表的变化,并将这些变化实时地同步到另一张表中。前提条件在开始之前,请确保已经设置好两个 S...
2024年11月04日
595 阅读
0 评论
0 点赞
1
2
3
4
...
26
CC BY-NC-ND