树敌真的很容易,有时候简单到令人痛心1111
当经历了背叛亲离,生死一线,失而复得,才明白不再逃避.
http://www.haotui.co
教育不111是灌输,而是点燃火焰
有时我沉默,不是不快乐,只是想把心净空有时候jdjd你需要退开一点,清醒一下,然后提醒自己,我是谁,要去哪里
走你正在走的路,不要怕没人与你分享
如何部署
111222333
开玩笑的啦。时间还不够
后台密码是什么啊
时间再拉长一点,让我有时间收拾一下心情
如果聚集负的感情,世界就会陷入负的洪流;反之聚集正的感情,世界就会循着正道而行
小时侯,幸福是很简单的事;长大了,简单是很幸福的事
他有一双好眼睛,就是他将我从黑暗的迷途中带了回来。1
看看看看
🏠️首页
🧰工具箱
📊统计
🕹️魁拔专区
更多
🇱🇰关于
🏘友链
🆕每日新闻
🎞视频
💹高清壁纸
Search
1
基于国外服务器搭建自己的VPN详细教程
6,362 阅读
2
最新tvbox绿豆盒子UI8影视APP源码新增后台添加直播及加密功能
3,334 阅读
3
2023彩虹易支付最新原版开源网站源码,完整的易支付源码,无后门
3,159 阅读
4
全新版本码支付个人免签支付系统源码 ThinkPHP框架开发 全开源(亲测)
3,001 阅读
5
多功能强大发卡平台,仿淘宝商城,资源站,一体化平台源码(亲测)
2,957 阅读
🥃技术分享
📠源码分享
📚课程分享
🗃号卡套餐
💾软件仓库
🔥活动线报
✨值得一看
Search
标签搜索
源码分享
技术分享
源码
css
安卓软件
课程分享
小程序
活动线报
软件
电脑软件
号卡
PHP
值得一看
HTML
js
AI
主题
教程
chatgpt
开源
老K博客
累计撰写
630
篇文章
累计收到
481
条评论
今日撰写
0
篇文章
首页
栏目
🥃技术分享
📠源码分享
📚课程分享
🗃号卡套餐
💾软件仓库
🔥活动线报
✨值得一看
页面
🧰工具箱
📊统计
🕹️魁拔专区
🇱🇰关于
🏘友链
🆕每日新闻
🎞视频
💹高清壁纸
用户登录
登录
搜索到
3
篇与
的结果
2025-03-30
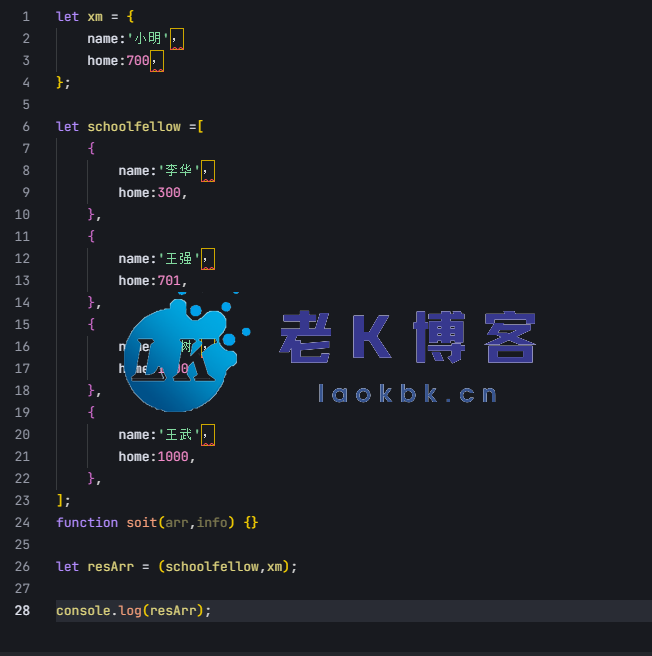
JavaScript前端面试:最近距离排序
最近看到的当面试题,非常简单。就是有这么一个小明个对象,他家的是700的距离,然后有一些别的对象,一个数组,每个人他的家有一个数字,现在让你对这个数组进行排序。 离小明越近的它就排在前面,越远的就排在后面,就这么个意思,比方说王强就离小明最近是,因为701基本是最近的他就在...
2025年03月30日
326 阅读
0 评论
0 点赞
2024-12-12
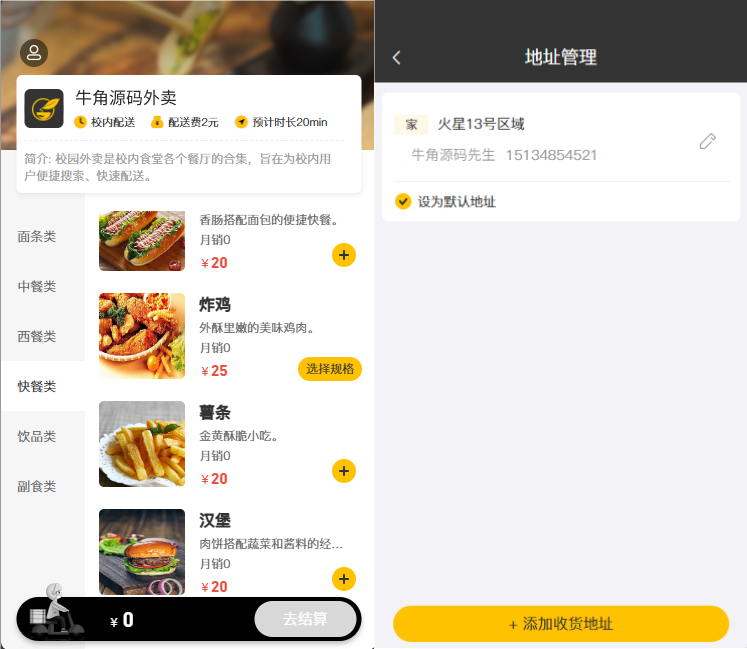
校园点餐订餐外卖跑腿Java源码
源码介绍一个非常实用的校园外卖系统,基于 SpringBoot 和 Vue 的开发。这一系统源于黑马的瑞吉外卖案例项目,经过进一步改进和优化,提供了更丰富的功能和更高的可用性。这个项目的架构设计非常有趣。虽然它采用了SpringBoot和Vue的组合,但并不是一个完全分离的...
2024年12月12日
383 阅读
0 评论
0 点赞
2023-12-26
Java开发网络爬虫:教你如何自动化抓取网页数据
在互联网时代,数据是非常宝贵的资源,如何高效地获取并处理这些数据成为许多开发者关注的焦点。而网络爬虫作为一种自动化抓取网页数据的工具,因其高效、灵活的特点,受到了广大开发者的青睐。本文将介绍如何使用Java语言开发网络爬虫,并提供具体的代码示例,帮助读者了解和掌握网络爬虫的...
2023年12月26日
446 阅读
0 评论
0 点赞
CC BY-NC-ND